Etcd数据库的基础使用
介绍
Etcd 是 CoreOS 基于 Raft 开发的高可用分布式 Key/Value 存储系统,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
- 简单:支持 curl 方式的用户 API (HTTP+JSON)
- 安全:可选 SSL 客户端证书认证
- 快速:单实例可达每秒 10000 次写操作
- 可靠:使用 Raft 实现分布式
Etcd 主要功能:
- 基本的 key-value 存储
- 监听机制
- key 的过期及续约机制,用于监控和服务发现
- 原子 CAS 和 CAD,用于分布式锁和 leader 选举
官网:https://etcd.io , 开源地址:https://github.com/etcd-io/etcd 。
集群部署(Docker方式)
执行脚本安装:
./install.sh
install.sh 脚本内容:
#!/bin/bash
DATA_PATH=/opt/mydocker/etcd3.4
COMPOSE_FILE_PATH=./docker-compose.yaml
mkdir -p ${DATA_PATH}
chmod 777 ${DATA_PATH}
mkdir -p ${DATA_PATH}/etcd1
chmod 777 ${DATA_PATH}/etcd1
mkdir -p ${DATA_PATH}/etcd2
chmod 777 ${DATA_PATH}/etcd2
mkdir -p ${DATA_PATH}/etcd3
chmod 777 ${DATA_PATH}/etcd3
docker-compose -f ${COMPOSE_FILE_PATH} stop
docker-compose -f ${COMPOSE_FILE_PATH} rm -f
docker-compose -f ${COMPOSE_FILE_PATH} up -d
docker-compose.yaml 配置:
version: '3'
services:
etcd1:
container_name: "etcd1"
restart: always
image: "quay.io/coreos/etcd:v3.4.7"
entrypoint: /usr/local/bin/etcd
command:
- '--name=etcd1'
- '--data-dir=/etcd_data'
- '--initial-advertise-peer-urls=http://etcd1:2380'
- '--listen-peer-urls=http://0.0.0.0:2380'
- '--listen-client-urls=http://0.0.0.0:2379'
- '--advertise-client-urls=http://etcd1:2379'
- '--initial-cluster-token=mys1cr2tt1k7n'
- '--heartbeat-interval=250'
- '--election-timeout=1250'
- '--initial-cluster=etcd1=http://etcd1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380'
- '--initial-cluster-state=new'
ports:
- "12379:2379"
volumes:
- /opt/mydocker/etcd3.4/etcd1:/etcd_data
etcd2:
container_name: "etcd2"
restart: always
image: "quay.io/coreos/etcd:v3.4.7"
entrypoint: /usr/local/bin/etcd
command:
- '--name=etcd2'
- '--data-dir=/etcd_data'
- '--initial-advertise-peer-urls=http://etcd2:2380'
- '--listen-peer-urls=http://0.0.0.0:2380'
- '--listen-client-urls=http://0.0.0.0:2379'
- '--advertise-client-urls=http://etcd2:2379'
- '--initial-cluster-token=mys1cr2tt1k7n'
- '--heartbeat-interval=250'
- '--election-timeout=1250'
- '--initial-cluster=etcd1=http://etcd1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380'
- '--initial-cluster-state=new'
ports:
- "22379:2379"
volumes:
- /opt/mydocker/etcd3.4/etcd2:/etcd_data
etcd3:
container_name: "etcd3"
restart: always
image: "quay.io/coreos/etcd:v3.4.7"
entrypoint: /usr/local/bin/etcd
command:
- '--name=etcd3'
- '--data-dir=/etcd_data'
- '--initial-advertise-peer-urls=http://etcd3:2380'
- '--listen-peer-urls=http://0.0.0.0:2380'
- '--listen-client-urls=http://0.0.0.0:2379'
- '--advertise-client-urls=http://etcd3:2379'
- '--initial-cluster-token=mys1cr2tt1k7n'
- '--heartbeat-interval=250'
- '--election-timeout=1250'
- '--initial-cluster=etcd1=http://etcd1:2380,etcd2=http://etcd2:2380,etcd3=http://etcd3:2380'
- '--initial-cluster-state=new'
ports:
- "32379:2379"
volumes:
- /opt/mydocker/etcd3.4/etcd3:/etcd_data
终端操作:
docker exec -it etcd1 etcdctl endpoint health
docker exec -it etcd1 etcdctl put secret 'code123'
docker exec -it etcd1 etcdctl get secret
docker exec -it etcd1 etcdctl --write-out="json" get secret
docker exec -it etcd1 etcdctl --write-out="table" member list
docker exec -it etcd1 etcdctl endpoint status --cluster -w table
docker exec -it etcd1 etcdctl get / --prefix
docker-compose ps master
Name Command State Ports
-----------------------------------------------------------------------------------------------------
etcd1 /usr/local/bin/etcd --name ... Up 0.0.0.0:12379->2379/tcp,:::12379->2379/tcp, 2380/tcp
etcd2 /usr/local/bin/etcd --name ... Up 0.0.0.0:22379->2379/tcp,:::22379->2379/tcp, 2380/tcp
etcd3 /usr/local/bin/etcd --name ... Up 0.0.0.0:32379->2379/tcp,:::32379->2379/tcp, 2380/tcp
对外暴露的端口是 12379,22379,32379,所以请求时:
endpoints := []string{"127.0.0.1:12379","127.0.0.1:22379","127.0.0.1:32379"}
快速入门
https://etcd.io/docs/v3.4/dev-guide/interacting_v3
场景使用:Leader选举
如果现在部署了一个微服务的多个副本,但只能由其中一个副本来执行某些操作,那么需要从这些副本中选出一个leader。场景有:定时器服务执行(多副本保持高可用)
可参考:
https://github.com/etcd-io/etcd/tree/main/client/v3/concurrency
示例:只有leader节点能执行crontab;lease租约有效期设为15s,leader节点异常,最长等待15s后由其他副本接力。
package main
import (
"context"
"fmt"
"go.etcd.io/etcd/client/v3"
"go.etcd.io/etcd/client/v3/concurrency"
"log"
"time"
)
const prefix = "/election-demo" // 可以认为是资源,或者锁的前缀,前缀下资源版本号最小的那个是leader
const prop = "local" // 值,任何值都可以,固定死
var leaderFlag bool
func main() {
endpoints := []string{"127.0.0.1:12379", "127.0.0.1:22379", "127.0.0.1:32379"}
donec := make(chan struct{})
cli, err := clientv3.New(clientv3.Config{Endpoints: endpoints})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
// 这里开始选举leader节点
go campaign(cli, prefix, prop)
go func() {
ticker := time.NewTicker(time.Duration(5) * time.Second)
for {
select {
case <-ticker.C:
// 只有leader才能执行定时器
if leaderFlag == true {
doCrontab()
}
}
}
}()
<-donec
}
func campaign(c *clientv3.Client, election string, prop string) {
for {
fmt.Println("campaign")
// 创建session,session参与选主,etcd的client需要自己传入。
// session中keepAlive机制会一直续租,如果keepAlive断掉,session.Done会收到退出信号
s, err := concurrency.NewSession(c, concurrency.WithTTL(15))
if err != nil {
fmt.Println(err)
time.Sleep(1 * time.Second) // 重新选举,不致于重试的频率太高
continue
}
fmt.Println("lease_id:", s.Lease())
// 创建一个新的选举election
e := concurrency.NewElection(s, election)
ctx := context.TODO()
// 调用Campaign方法,成为leader的节点会运行出来,非leader节点会阻塞在里面
if err = e.Campaign(ctx, prop); err != nil {
fmt.Println(err)
time.Sleep(1 * time.Second) // 重新选举,不致于重试的频率太高
continue
}
// 运行到这的协程,成为leader
fmt.Println("elect: success")
leaderFlag = true
select {
// 如果因为网络因素导致与etcd断开了keepAlive,会收到信号,重新选举
case <-s.Done():
leaderFlag = false
fmt.Println("elect: expired")
time.Sleep(1 * time.Second) // 重新选举,不致于重试的频率太高
continue
}
}
}
func doCrontab() {
fmt.Println("doCrontab")
}
选举原理
etcd中concurrency包下已经帮我们实现好了选主,我们只需要调用其api实现就可以了,下面我们分析下etcd是如何实现选主机制的。直接进行源码分析:
// Campaign puts a value as eligible for the election on the prefix
// key.
// Multiple sessions can participate in the election for the
// same prefix, but only one can be the leader at a time.
//
// If the context is 'context.TODO()/context.Background()', the Campaign
// will continue to be blocked for other keys to be deleted, unless server
// returns a non-recoverable error (e.g. ErrCompacted).
// Otherwise, until the context is not cancelled or timed-out, Campaign will
// continue to be blocked until it becomes the leader.
// 多个etcd的session可以通过prefix来参与选举。但是只有一个session能成为leader。
// Campaign方法会阻塞,直到session成功成为leader才返回。
func (e *Election) Campaign(ctx context.Context, val string) error {
s := e.session
client := e.session.Client()
// 根据前缀和租约创建当前key
k := fmt.Sprintf("%s%x", e.keyPrefix, s.Lease())
// 如果是第一次创建key,那么key的revision为0
// 这里用到了etcd的事务,如果if判断为true,那么put这个key,否则get这个key;最终都能获取到这个key的内容。
txn := client.Txn(ctx).If(v3.Compare(v3.CreateRevision(k), "=", 0))
txn = txn.Then(v3.OpPut(k, val, v3.WithLease(s.Lease())))
txn = txn.Else(v3.OpGet(k))
resp, err := txn.Commit()
if err != nil {
return err
}
e.leaderKey, e.leaderRev, e.leaderSession = k, resp.Header.Revision, s
// 这里是事务中if判断为false,即执行了else
if !resp.Succeeded {
kv := resp.Responses[0].GetResponseRange().Kvs[0]
e.leaderRev = kv.CreateRevision
if string(kv.Value) != val { // 判定val是否相同,不相同的话,在不更换leader的情况下,更新val
if err = e.Proclaim(ctx, val); err != nil {
e.Resign(ctx)
return err
}
}
}
// 等待prefix前缀下所有比当前key的revision小的其他key都被删除后,才返回,竞选为leader
_, err = waitDeletes(ctx, client, e.keyPrefix, e.leaderRev-1)
if err != nil {
// clean up in case of context cancel
select {
case <-ctx.Done():
e.Resign(client.Ctx())
default:
e.leaderSession = nil
}
return err
}
e.hdr = resp.Header
return nil
}
func waitDelete(ctx context.Context, client *v3.Client, key string, rev int64) error {
cctx, cancel := context.WithCancel(ctx)
defer cancel()
var wr v3.WatchResponse
// 这里watch指定的key,对于这个key所有events事件,都会收到服务端的推送。
wch := client.Watch(cctx, key, v3.WithRev(rev))
for wr = range wch {
for _, ev := range wr.Events {
if ev.Type == mvccpb.DELETE { // 如果当前这个key被删除了,那么会退出这个方法,watch下一个key。
return nil
}
}
}
if err := wr.Err(); err != nil {
return err
}
if err := ctx.Err(); err != nil {
return err
}
return fmt.Errorf("lost watcher waiting for delete")
}
// waitDeletes efficiently waits until all keys matching the prefix and no greater
// than the create revision.
func waitDeletes(ctx context.Context, client *v3.Client, pfx string, maxCreateRev int64) (*pb.ResponseHeader, error) {
// option,获取createRevision不大于maxCreateRev的key,只取最后一个revision最大的
getOpts := append(v3.WithLastCreate(), v3.WithMaxCreateRev(maxCreateRev))
for {
// 获取前缀prefix下,所有比指定revision小的key
resp, err := client.Get(ctx, pfx, getOpts...)
if err != nil {
return nil, err
}
if len(resp.Kvs) == 0 {
return resp.Header, nil
}
lastKey := string(resp.Kvs[0].Key)
// 去watch revision最大的key,这里也会阻塞的watch。外层有循环判断,要等所有比revision小的key的没了,才退出。
// 下方有具体的说明
if err = waitDelete(ctx, client, lastKey, resp.Header.Revision); err != nil {
return nil, err
}
}
}
总体来说还是比较好理解的,主要是利用watch机制来实现了节点在不是leader的时候的阻塞机制。
可以看到,每个节点都创建了自己的key,但是这些key的前缀是一致的,选主是根据前缀去选主的。
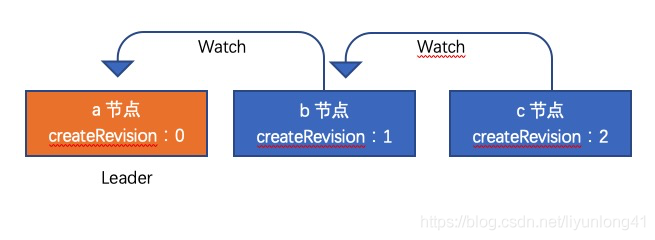
如果有a,b,c三个节点同时去竞选,分别对应竞选的createRevision是0,1,2,那么每个节点会watch比自己createRevision小并且最大的节点,这是个循环的过程,等到所有比自己createRevision小的节点都被删除后,自己才成为leader。
对应的,a节点会成为leader,b节点在watch a节点,c节点在watch b节点。如果b节点key被删除了,c节点会去watch a节点。
如果a节点key被删除了,b节点会成为leader。